
What Does A Robust Serverless Architecture Look Like?

Serverless is one of the latest industry buzzwords — but like anything in tech, if it’s not set up properly, your development investments can fall apart like a house of cards.
All the major cloud players now offer some sort of serverless architecture support — AWS with Lambda, Google with Cloud Functions and Microsoft with Azure Functions. The open-sourced and free Serverless framework is also designed and created to help developers automate their processes and create better serverless code.
The rationale behind serverless is that it’s event-driven with the ability to scale automatically without the need for infrastructure set up or intervention. But the main question that’s not asked often enough is — what does a robust serverless architecture look like?
Consolidated and Isolated Event-Driven by Nature
It’s easy to fall into the trappings of writing a function for anything imaginable. When it comes to serverless, it’s easy to boot up a function that performs a job. That job can be activated through an automated chron job, triggered through gateways, data changes, and code pipeline activities.
While this sounds fantastic for isolated cases, larger applications in a serverless environment require the architect to look at the overall set of expected events and design functions as a modular network.
In a way, building apps in a serverless manner is a deconstructed approach to software development. It can be booted up in parts without dependencies and deliver rapid problem-solving solutions.
A robust serverless architecture enforces a certain code condensation and modularity in order to minimize interdependence. Its statelessness disconnects the functions from one another and a persistent data source becomes a single space for truthiness.
Channing functions can cause a serial domino effect if something fails. A parallel approach to the relationship between functions mitigates this risk.
Take a look at the diagrams below, for example.

The above process flow is a default that some of us can fall into when creating serverless code. This is because it’s easy to think in a traditional dependency injection model where one function triggers another. We may put in a recursion if the requirements make sense. However, when applied to serverless applications, a break in the flow can ultimately cause a break for the outcome, with no contingency plan.
This is because a serial approach doesn’t satisfy the need for each function to be truly independent. The trigger for the above approach is a serverless function calling another, meaning that it has the potential to pass data along the pipeline without validation or proper state management.
Take a look at the following diagram. It has the same three serverless functions but are connected to one another via a stateful trigger.
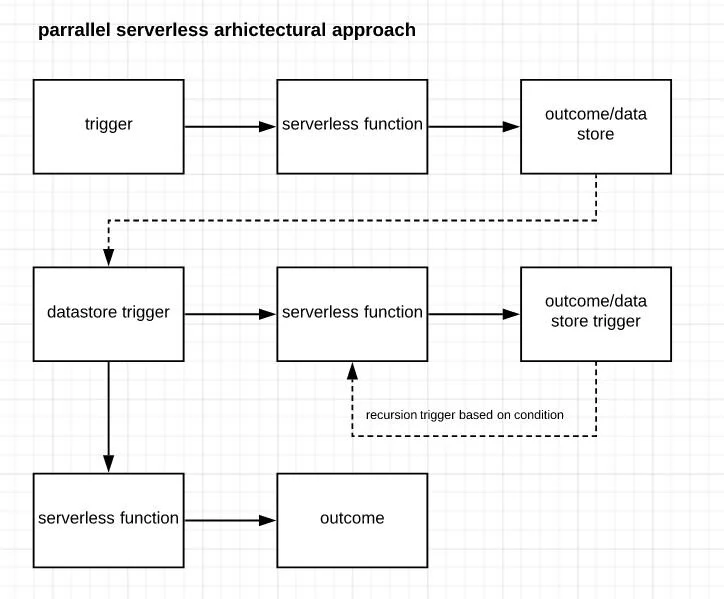
This methodology may appear more complex, but if you look at where the potential breaking points are, they are based on the triggers and not the function.
When recursions are implemented, the trigger is based on something that is persistent, rather than a transient space where you’re at risk of losing the output.
The architecture also allows for multiple pieces of code to run. Serverless and its associated tableless data storage are cheap. In part, this is because its inception is designed on the idea of high volume usage.
While the first diagram runs one function at a time in order to trigger the other, therefore appearing to use less computational power, the second diagram allows for two functions to run in an isolated manner but remain connected through the data triggers.
. . .
When it comes to a robust serverless architecture, the structure of code rests on a developer’s ability to create isolated solutions for a bigger picture. The code is often functional in nature as reusability rests on its ability to process data without class-based blueprints.
A robust serverless architecture for larger software takes into consideration where the potential breaks are and where data could be lost. By centralizing triggers around permanency, it solves this issue and reduces the risk caused by the transient nature of serverless.
Functional parallelism is one of the architectural methods that can be used for a robust serverless architecture. When it comes to triggers, implementing permanency is a good practice for data protection and validations. It’s also a way to deal with the expected statelessness of serverless.
Co-authored by:
Dave Wesley ~ President, SRG
LinkedIn
Aphinya Dechalert ~ Marketing Communications, SRG
LinkedIn